TinyTM - Roadmap
Use Cases
TinyTM aims to cover the following use cases, more or less in the given
order.
-
Single Freelancer
A single freelance translator can use TinyTM to translate his texts in MS-Word.
-
Small Translation Agency
A small translation
uses TinyTm in order to manage their internal translation processes
in MS-Word.
-
XML Translation
One or more translators
translate tagged text such as XML or HTML.
-
TMX Im-/Export
A translation company
wants to im-/export TM assets in TMX format.
-
Browser Translation
One or more translators
a) upload a structured text (XML or HTML) into a TinyTM web GUI, b)
translate the text with TM support and c) download the result.
-
Large Translation Agency
A large translation
agency wants to consolidate all translations on TinyTM.
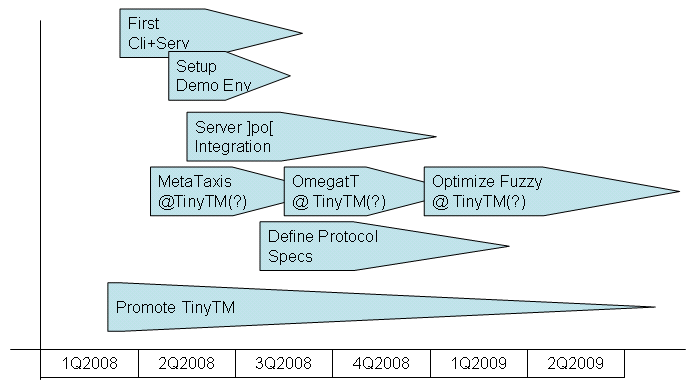
Roadmap Steps
In order to cover important use cases as quickly as possible, we propose
to develop the following TinyTM milestones.
- Create a basic Client and Server
The very first combination
is a MS-Word macro that accesses a PostgreSQL server directly via ODBC.
Covers part of Use Cases 1 and 2 (without administration pages).
- Setup public demo server
Once the basic Client and
Server are ready, we need to setup a public demo server where interested
users can download a preconfigured Client with a hard-coded Server address,
so that they can immediately test the environment. Does not cover a
specific Use Case, but is important for the dissemination of TinyTM.
- Integrate with Omega-T
OmegaT is an open-source
translation memory written in Java capable of editing XML and HTML files.
We would add a TinyTM backend interface OmegaT, providing OmegaT with
fuzzy matching.�Covers Use Case 3 and 4.
- User & Group Administration for Server
The ]project-open[
team will provide a reference implementation of user and group administration
by integrating TinyTM with ]po[. Covers Use Cases 1 and 2 completely.
- Wrap-up Protocol Specs
Once the demo environment
– more or less – works we would release the protocol specs
so that other clients can access the server.
- Optimize Fuzzy Retrieval for Large TMs
We need to
optimize the backend fuzzy retrieval in order to deal with TMs beyond
a certain size. In particular, we would need to introduce something
like a "trigram based fuzzy index" or similar concepts.�
This is one of the requirements for Use Cases 6 and 7.
Roadmap